2022/7/25
このチュートリアルはRakeをはじめて学ぶ人を対象にしていますが、すでにRakeを知っている人にも役立つ内容になっています。 このチュートリアルの特長は
このチュートリアルを通して、様々な開発にRakeを活用できる力をつけましょう。
文中に例として書かれているソースコードは、GitHubのレポジトリRake tutorial for bginners jpにありますので、ダウンロードして使ってください。
文中に[R]という記号で始まる段落は、「Ruby上級者向けの解説」です。 上級とは、ほぼ「クラスを記述できるレベル」を指します。 上級以外の方はこの部分を飛ばしてください。
RakeはRubyのアプリケーションです。 RubyのインストールについてはRubyの公式ホームページを参考にしてください。 Rakeは「Rubyの標準添付ライブラリ」なので、インストールされたRubyの中に含まれることが多いですが、もしそうでないときは、
などの方法でインストールしてください。
Rakeは、Makeと同様の機能を、Rubyプログラムとして実装したアプリケーションです。
Makeは、Cでコンパイルするときに、コンパイル過程全体をコントロールするために開発されたプログラムです。 しかし、MakeはCだけではなく、いろいろなコンパイラやトランスレータ(ある形式から別の形式に変換するプログラム)を制御することができます。 便利なMakeですが、その文法はマニアックです。 初歩的な使い方をしているうちは、分かりやすいのですが、使えば使うほど分かりにくくなってきます。 例えばこんな感じです。
application: $(OBJS)
$(CC) -o $(@F) $(OBJS) $(LIBS)
$(OBJS): %.o: %.c $(HEADER)
$(CC) -fPIC -c -o $(@F) $(CFLAGS) $<それに対してRakeは
という利点があります。
まず、コマンドのrakeとカレントディレクトリに置くRakefileというファイルがポイントになります。
rakeコマンドは引数にタスク名(タスクは後で説明します)をとり、
$ rake helloなどの形で使います。
この例では、引数helloはタスク名です。
このときrakeは次のことを順に実行します。
「Rakefileにタスクの定義を書く」ことが、rakeを使う際のポイントになります。 当然、コマンドラインから呼び出されるタスクはRakefileの中で定義されていなければなりません。
[R] 「タスクの定義を書く」「タスクを定義する」などは、Rubyのドキュメントで使われている言い回しです。 Rubyに熟練している人は、これが具体的に何を意味するか気になるかもしれません。 Ruby的には「Taskクラスのインスタンスを生成する」ことを意味します。
タスクはオブジェクトで、名前、事前タスク(前提条件)、アクションを持ってます。 事前タスクとアクションは無くても構いません。
それでは、まず名前だけを持っているタスクを作成してみましょう。 Rakefileに次のように書き込みます。
task :simple_tasktaskはタスクを定義するためのコマンド(命令)だと考えてください。
一般に「コマンド」はプログラム言語において、コンピュータに何かをさせるためのものです。
例えば、Shellでは、「cd」はカレント・ディレクトリを移動する「コマンド」です。
「cd
/var」によって、カレントディレクトリが「/var」に移動しますが、それは「/var引数を与えてcdコマンドを実行した」ことの結果なのです。
同様に「task」コマンドには引数「:simple_task」が与えられています。
そして「taskコマンドを実行することにより、simple_taskを名前とするタスクが作成される」のです。
なお、引数の:simple_taskはシンボルですが、文字列を使っても構いません。
task "simple_task"両者に対してtaskコマンドが作成するタスクは全く同じです。
実は、taskコマンドは、Rubyの文法から見ると、taskメソッドの呼び出しで、:simple_taskはtaskメソッドへの引数です。
ですので、今後はtaskを「コマンド」あるいは「メソッド」ということがありますが、
で使い分けをしています。 細かいことになるので、あまり気にしなくても構いません。
[R] Rubyの文法から見た場合、
taskコマンドは「メソッド呼び出し」で、:simple_taskはtaskメソッドの引数です。 Rubyではメソッド呼び出しの引数にカッコを付けても付けなくても良いのでこのように書けるのです。 もしカッコを付けるのならば、task("simple_task")となります。 (taskとカッコの間にはスペースを入れない)。 どちらでも定義できますが、カッコ無しを用いるのが良いです。
「タスクを定義する」とは「Taskクラスのインスタンスを生成する」ことです。 インスタンスの生成には通常newメソッドが使われますが、Task.newよりtaskメソッドの方が便利です。 なお、taskメソッドでは、その実行の中で「Task.new」が呼び出され、タスクのインスタンスが生成される仕組みになっています。
タスク「simple_task」には事前タスクとアクションは定義されていません。
コマンドラインからタスクを実行してみましょう。 (注:レポジトリのexampleフォルダ内のRakefileの使い方はこのセクションの最後に書いてあります)。
$ rake simple_taskタスクは呼び出されているのですが、アクションが無いため、見た目には何も起こりません。 タスクが定義できているかどうかは、次のようにするとわかります。
$ rake -AT
rake simple_task #オプションATは登録されているすべてのタスクを表示します。 これで、simple_taskが定義されていることがわかりました。
この例を読者自身が作って実行するのは容易にできますが、このレポジトリのexampleフォルダにすでにRakefileが用意されています。 ここでその使い方を説明しておきましょう。
’example/example1`にカレントディレクトリを移動します。
$ cd example/example1
$ ls
Rakefile1 Rakefile2 Rakefile3 Rakefile4フォルダ内にあるRakefile1が先程のRakefileになります。
$ cat Rakefile1
task :simple_taskファイル名がRakefileでなく「Rakefil1」と「1」がついているため、単に「rake
simple_task」では「Rakefile1」を読んでくれません。
そこで、-fオプションを使ってRakefileを指定します。
$ rake -f Rakefile1 simple_task
$ rake -f Rakefile1 -AT
rake simple_task # 今後も、exampleフォルダ内のRakefileを使うときには、ファイル名の指定が必要になります。
アクションは、taskメソッド呼び出しのブロックで表します。
task :hello do
print "Hello world!\n"
endこのタスクはhelloという名前です。
helloには事前タスクはありません。 アクションは「Hello
world!」と画面表示する、というものです。
では、このタスクを実行してみましょう。
(example/example1フォルダ内のRakefile2を-fオプションで指定してください)。
$ rake hello
Hello world!タスクhelloが呼び出され、そのアクションが実行されて「Hello world!」の文字列が表示されました。
[R] Rubyにはブロックを(1)波カッコ(
{と})で表す(2)doとendで表す、の2つの方法があります。 Rakefileではどちらも動作しますが、読みやすさの点からdoとendを使うのが良いでしょう。 また、波カッコを使う場合、次のように書くと動作しません。task :hello {print "Hello world!\n"}これは、do-endより波カッコの方が強く結合するために起こるエラーです。 Rubyのドキュメントが参考になるので見てください。 これを解消するには、引数にカッコをつけます。
task(:hello) {print "Hello world!\n"}Rakeでは、「taskがあたかもコマンドであるかのように表現したい」ということがあります。 波カッコを使うとそれができませんから、動作はするけれども推奨はできないのです。
RakeはRuby文法の自由さ(引数のカッコを省略できるなど)を使って、taskなどのコマンドを提供しています。 このように、特定の分野のために作られたコマンドをもつ言語を「DSL(Domain-Specific Language)」といいます。 do-end推奨の背景にはDSLの考え方があります。
あるタスクが事前タスクを持っている場合、そのタスクが呼び出され(実行され)る前に事前タスクを呼び出します。
タスクの定義は
task タスク名 => 事前タスク(の配列)do
アクション
endのようになります。
「タスク名=>事前タスク(の配列)」のところは、Rubyのハッシュです。
メソッド呼出の末尾にハッシュを渡す場合は
カッコ({と}) を省略することができます。
省略しなければ「{タスク名 =>
事前タスク(の配列)}」となりますが、これでも動作します。
また、タスク名がシンボルの場合、例えば「:abc => “def”」と書くのを「abc: “def”」と書くことができます。 同様に、「:abc => :def」と「abc: :def」は同じです。
次の例では、firstとsecondという2つのタスクがあり、firstがsecondの事前タスクになっています。
task second: :first do
print "Second.\n"
end
task :first do
print "First.\n"
endタスクsecondを呼び出すと、事前タスクであるfirstがその前に呼び出されます。
firstを実行 => secondを実行という順になります。
$ rake second
First.
Second.(example/example1ファルダでは、Rakefile3を-fオプションで指定してください)。
歌川さんの味玉のレシピをMakefileで記述するが面白かったので、そのRake版を作ってみました。
# 味玉をつくる
task :お湯を湧かす do
print "お湯を湧かします\n"
end
task 卵を茹でる: :お湯を湧かす do
print "卵を茹でます\n"
end
task :'8分待つ' => :卵を茹でる do
print "8分待ちます\n"
end
task ボウルに氷を入れる: :'8分待つ' do
print "ボウルに氷を入れます\n"
end
task ボウルに水を入れる: :ボウルに氷を入れる do
print "ボウルに水を入れます\n"
end
task ボウルに卵を入れる: :ボウルに水を入れる do
print "ボウルに卵を入れます\n"
end
task 卵の殻を剥く: :ボウルに卵を入れる do
print "卵の殻を剥きます\n"
end
task :ジップロックに日付を書く do
print "ジップロックに日付を書きます\n"
end
task ジップロックにめんつゆを入れる: [:ジップロックに日付を書く, :卵の殻を剥く] do
print "ジップロックにめんつゆを入れます\n"
end
task ジップロックに卵を入れる: :ジップロックにめんつゆを入れる do
print "ジップロックに卵を入れます\n"
end
task 一晩寝かせる: :ジップロックに卵を入れる do
print "一晩寝かせます\n"
end
task 味玉: :一晩寝かせる do
print "味玉ができました\n"
end実行してみます。
(example/example1フォルダでは、Rakefile4を-fオプションで指定してください)。
$ rake 味玉
ジップロックに日付を書きます
お湯を湧かします
卵を茹でます
8分待ちます
ボウルに氷を入れます
ボウルに水を入れます
ボウルに卵を入れます
卵の殻を剥きます
ジップロックにめんつゆを入れます
ジップロックに卵を入れます
一晩寝かせます
味玉ができましたすでに呼び出されたタスクは実行されません。 つまり「タスクの実行は1度だけ」です。
例えば、味玉のRakefileで
task ジップロックに卵を入れる: :ジップロックにめんつゆを入れる doのところを
task ジップロックに卵を入れる: [:ジップロックにめんつゆを入れる, :卵の殻を剥く] doとすると、「卵の殻を剥く」が2箇所で事前タスクになります。 呼び出しが2回ありますが、実行は1回だけなので、実行結果は同じになります。
[R] タスクのインスタンス・メソッドに「invoke」(呼び出し)と「execute」(実行)があります。 invokeはアクションを一度だけ実行しますが、executeはそのメソッドが呼ばれた回数だけ何度でも実行します。 それで、Rubyのドキュメントでは「呼び出し」と「実行」の2つの言葉を区別して使っているようです。 このチュートリアルでは使い分けが曖昧な箇所がありますが、大きな混乱はないと思っています。 なお、invokeは自身のタスクを呼び出す前に事前タスクを呼び出しますが、executeは事前タスクを呼び出しません。
今までタスク名にシンボルを使ってきましたが、文字列を使うこともできます。
task "simple_task"
task "second" => "first"このような書き方も可能です。 シンボルでハッシュを記述するには「{abc: :def}」のような書き方ができますが、シンボルの最初に数字がくるときにはこれが使えません。 「{0abc: :def}」や「{abc: :2def}」はシンタックス・エラーになります。 「{:‘0abc’ => :def}」「{abc: :‘2def’}」のように書かなければなりません。 文字列ではこのような心配がなく、シングルクォートあるいはダブルクォートで囲めばエラーになりません。
慣例としては
task abc: %w[def ghi]の書き方が多く用いられるようです。
%wは空白で区切られた文字列の配列を返します。
%w[def ghi]と["def", "ghi"]は同じです。
Rubyのドキュメントの%記法を参考にしてください。
味玉の例で%記法を使うと
task ジップロックにめんつゆを入れる: %w[ジップロックに日付を書く 卵の殻を剥く] doとなります。
この章ではファイルタスクを説明します。 ファイルタスクはRakeにおいて最も重要なタスクです。 ファイルタスクのためにRakeがあると言っても過言ではありません。
ファイルタスクはタスクの一種です。 ファイルタスクにも一般のタスクと同じように「名前」「事前タスク」「アクション」があります。 一般のタスクとの違いは次の3点です。
これ以外は一般のタスクと同じように「タスクの呼び出しの前に事前タスクを呼び出す」「タスクの実行は一度だけ」です。
それでは、ファイルタスクのアクションを実行する上での条件とは何でしょうか。 条件は2つあります。
[R]ここでいうmtime(ファイル内容変更時間)はRubyのFile.mtimeメソッドの値です。 Linuxのファイルにはatime, mtime, ctimeの3つのタイムスタンプがあります。
- atime 最後にアクセスされた時刻
- mtime 最後に変更された時刻
- ctime 最後にinodeが変更された時刻
RubyのFile.mtimeメソッドはこのmtimeを返します。(C言語で書かれたオリジナルのRubyはCのシステムコールでその値を取得しています)
それでは具体例を見ていきましょう。 ここではテキストファイル「a.txt」のバックアップファイル「a.bak」を作ることを考えます。 単純にファイルをコピーすれば良いので、
$ cp a.txt a.bakで出来ますが、練習のためにRakefileにしてみます。
file "a.bak" => "a.txt" do
cp "a.txt", "a.bak"
endこのRakefileの内容を説明します。
cp "a.txt", "a.bak"です。cpメソッドは第1引数ファイルを第2引数ファイルにコピーするメソッドです。
このメソッドはFileUtilsモジュールで定義されています。
FileUtilsはRubyの標準添付ライブラリですが、ビルトインではないため、通常はrequire 'fileutils'をプログラムに書かなければなりません。
しかし、Rakeが自動的にrequireするのでRakefileにそれを書く必要はありません。
タスク「a.bak」が呼び出されると、その実行の前に事前タスク「a.txt」が呼び出されます。 ところが、Rakefileにはタスク「a.txt」の定義が書かれていません。 Rakeは事前タスクの定義が無いときにどのように振る舞うのでしょうか? Rakeはファイル「a.txt」存在するならば、ファイルタスク「a.txt」を名前だけのタスク(事前タスクとアクションは無い)として自ら定義します。 そしてそのタスクを呼び出しますが、アクションが無いので何もせずに「a.bak」の呼び出しに戻ります。 もし「a.txt」が存在しなければエラーになります。
それでは、コマンドラインから実行してみましょう。
(example/example2で試すには、rake -f Rakefile1 a.bakとしてください。
lsの結果はexample/example2では異なります)
$ ls
Rakefile a.txt
$ rake a.bak
cp a.txt a.bak
$ ls
Rakefile a.bak a.txt
$ diff a.bak a.txt
$ rake a.bak
$ここでは、最も基本的なファイルタスクの使い方を学びました。
次に3つのファイルをバックアップするRakefileについて考えてみましょう。 新たに「b.txt」と「c.txt」というファイルを作っておきます。 Rakefileのもっとも初歩的な書き方は、次のようなものでしょう。
file "a.bak" => "a.txt" do
cp "a.txt", "a.bak"
end
file "b.bak" => "b.txt" do
cp "b.txt", "b.bak"
end
file "c.bak" => "c.txt" do
cp "c.txt", "c.bak"
endここには、3つのファイルタスクが定義されています。
それを実行してみましょう。
(example/example2では-f Rakefile2をつけて実行してください)
あらかじめ、「a.bak」は削除しておきます。
$ ls
Rakefile a.txt b.txt c.txt
$ rake a.bak
cp a.txt a.bak
$ rake b.bak
cp b.txt b.bak
$ rake c.bak
cp c.txt c.bak
$ ls
Rakefile a.bak a.txt b.bak b.txt c.bak c.txt皆さん既に気がついたことと思います。 「自分だったらこんなことしない。rakeを3回使うのならcpを3回使うのと変わらないじゃないか」。 その通りです。
一度のRake実行で3個のファイルをコピーしたいですね。 これは、一般のタスクと3つのファイルタスクを関連付けることで実現できます。 最初に「copy」タスクを作り、3つのファイルタスクをその事前タスクにしてみましょう。
task copy: %w[a.bak b.bak c.bak]
file "a.bak" => "a.txt" do
cp "a.txt", "a.bak"
end
file "b.bak" => "b.txt" do
cp "b.txt", "b.bak"
end
file "c.bak" => "c.txt" do
cp "c.txt", "c.bak"
end実行してみます。
(example/example2では-f Rakefile3をつけて実行してください)
$ rm *.bak
$ rake copy
cp a.txt a.bak
cp b.txt b.bak
cp c.txt c.bak一度のrake実行で3つのコピーができました。
リファクタリングしましょう。 2つのことを改善します。
backup_files = %w[a.bak b.bak c.bak]
task default: backup_files
backup_files.each do |backup|
source = backup.ext(".txt")
file backup => source do
cp source, backup
end
end実行してみます。
(example/example2では-f Rakefile3をつけて実行してください)
$ rm *.bak
$ rake
cp a.txt a.bak
cp b.txt b.bak
cp c.txt c.bak
$ touch a.txt
$rake
cp a.txt a.bak
$例の最後で「touch」を使ってmtimeを変更しましたが、通常はエディタでファイルを上書きするときにmtimeの更新が起こります。 つまり、元ファイルが新しくなるとファイルタスクのアクションを実行する条件が整うことになります。
少々リファクタリングを追加し、ブロックの中でタスクのインスタンスを使う方法を紹介します。
ファイルタスクの定義の部分を次のように変更します。
file backup => source do |t|
cp t.source, t.name
endブロックに新たにパラメータ「t」が加わりました。 「t」にはファイルタスク「backup」が代入されます。 (Ruby的にはそのインスタンスが代入されます)
taskメソッドのブロックでも同じパラメータが使えます。
タスクやファイルタスクには便利なメソッドがあります。
name タスクの名前を返すprerequisites 事前タスクの配列を返すsources 自身が依存するファイルのリストを返すsource
自身が依存するファイルのリストの最初の要素を返すこの他にもメソッドはありますが、よく使われるのは上の4つのメソッドです。
新しいファイルタスクの定義では、そのアクションが「t.source」から「t.name」にコピーするように変わっています。
これは、それぞれ「source」と「backup」になりますから、以前のファイルタスクと内容的には同じです。
(example/example3では-f Rakefile5をつけて実行してください)
これまでのバックアップは「.txt拡張子のファイルを.bak拡張子のファイルにコピーする」というものでした。 これを「a.bak」というファイル名にあてはめれば、「a.txtをa.bakにコピーする」というアクションを持つファイルタスクが得られます。 このように、ファイルタスクを作るための規則をルールと呼びます。 ルールは「rule」メソッドで定義できます。 具体的に「rule」を使ったRakefileの例を見てみましょう。
backup_files = %w[a.bak b.bak c.bak]
task default: backup_files
rule '.bak' => '.txt' do |t|
cp t.source, t.name
endはじめの3行は今までと変わりません。 3行目の定義によると、defaultの事前タスクは「a.bak」「b.bak」「c.bak」ですが、それらのタスクの定義は書かれていません。 Rakeは、事前タスクの定義がないときは、その呼び出しの直前に事前タスクの定義を試みます。
この例におけるルールは次のようになります。
3つのタスク「a.bak」「b.bak」「c.bak」はすべてルールに合致するので、ルールに従ってタスクが定義されます。
それでは、実行してみましょう。
(example/example2では-f Rakefile6をつけて実行してください)
$ rm *.bak
$ rake
cp a.txt a.bak
cp b.txt b.bak
cp c.txt c.bak
$今までと同じように動作しました。
ruleメソッドの'.bak'の部分は、Rakeが正規表現/\.bak$/に変換します。
この正規表現とタスク名の「a.bak」「b.bak」「c.bak」が比較されるのです。
そこで、最初から正規表現にしておいてもルールを定義できます。
(example/example2では-f Rakefile7をつけて実行してください)
rule /\.bak$/ => '.txt' do |t|
cp t.source, t.name
end[R] このことは、「拡張子の一致」だけでなく「任意のパターンに対する一致」を可能にします。 例えば、バックアップファイルを「~a.txt」のように先頭にチルダ「
~」を付けるように変更することが可能です。backup_files = %w[~a.txt ~b.txt ~c.txt] task default: backup_files rule /^~.*\.txt$/ => '.txt' do |t| cp t.source, t.name endところが、これではエラーになってしまいます。
$ rake rake aborted! Rake::RuleRecursionOverflowError: Rule Recursion Too Deep: [~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt] Tasks: TOP => default (See full trace by running task with --trace)これは、
=> '.txt'の部分が良くないのです。 これだと「~a.txt」の依存ファイルが、タスク名の「~a.txt」の拡張子を「.txt」に変えたものである「~a.txt」になってしまいます。 つまりタスク名と依存タスク名が同じなので、ルールを適用するときに無限ループに陥ってしまうのです。 Rakeでは、16回のループが起きたときにエラーとして処理します。これを避けるには、依存ファイルをProcオブジェクトで定義します。
backup_files = %w[~a.txt ~b.txt ~c.txt] task default: backup_files rule /^~.*\.txt$/ => proc {|tn| tn.sub(/^~/,"")} do |t| cp t.source, t.name endprocメソッドのブロックの引数には、タスク名(例えば「~a.txt」)がRakeによって渡されます。 Procインスタンスの生成には、lambdaメソッドや「->( ){ }」(Rubyのドキュメント参照)も使えます。
実行してみます。 (
example/example2では-f Rakefile8をつけて実行してください)$ rake cp a.txt ~a.txt cp b.txt ~b.txt cp c.txt ~c.txt $
このセクションではファイルタスクをサポートする便利な機能を解説します。 具体的には「ファイルリスト」「パスマップ」「ディレクトリータスク」です。
ファイルリストは、ファイル名の配列のようなオブジェクトです。 文字列の配列と同様の操作ができ、さらにいくつかの便利な機能を備えています。
まずファイルリストのインスタンスの作り方から説明しましょう。
クラス名「FileList」に[ ]をつけ、そのカッコのなかにファイル名をコンマで区切って書きます。
これで、そのファイルを持つファイルリストができます。
files = FileList["a.txt", "b.txt"]
p files
task :defaultデフォルトタスクを定義しないと、コマンドラインからrakeを実行したときにエラーになります。
それを防ぐために何もしないデフォルトタスクを定義してあります。
ここでRakeの動作をもう一度確認しておきましょう。
2番めのRakefileロード時に、ファイルリストが作成され、表示され、デフォルトタスクの定義が行われます。 これらは「タスク呼び出し」前に行われていることに注意してください。
実行してみます。
(example/example3では-f Rakefile1をつけて実行してください)
$ rake
["a.txt", "b.txt"]
$シェルで良く使われるGlobパターンも使えます。
files = FileList["*.txt"]
p files
task :default実行してみます。
(example/example3では-f Rakefile2をつけて実行してください)
lsやrakeの結果はそのディレクトリに含まれるファイルによって異なります。
Rakefile3以降でもlsやrakeの結果が異なることがあります)
$ ls
Rakefile a.txt b.txt c.txt '~a.txt'
$ rake
["a.txt", "b.txt", "c.txt", "~a.txt"]
$GlobパターンについてはRubyのドキュメントを参考にしてください。
すべてのテキストファイルをバックアップすることを考えてみます。 ここでは、「テキストファイル」を「拡張子が.txtのファイル」としておきます。 このとき、「すべて」というのは「現時点でのすべて」ではなく、「Rakeを実行する時点でのすべて」です。 将来テキストファイルが追加されたり、削除されたりする可能性がありますから、「現時点でのすべてのテキストファイル」と「Rakeを実行する時点でのすべてのテキストファイル」は同じとは限りません。 ですから、Rakefileの記述の中に、その時点でのテキストファイルを捕まえる仕組みを作らなければなりません。 それにはファイルリストを使います。
files = FileList["*.txt"]さて、この中に「~a.txt」が含まれていますが、これはオリジナルが「a.txt」であるバックアップファイルですから、コピーの対象から外します。 そのときにはexcludeメソッドを使います。
files = FileList["*.txt"]
files.exclude("~*.txt")
p files
task :defaultexcludeメソッドは、与えられたパターンを自身の除外リストに加えます。
実行してみましょう。
(example/example3では-f Rakefile3をつけて実行してください)
$ rake
["a.txt", "b.txt", "c.txt"]
$「~a.txt」が取り除かれました。
今ファイルリストにはオリジナルのファイル(コピー元のファイル)がセットされました。 一方、ファイルタスクの名前はバックアップファイル名です。 例えば「a.txt」を「a.bak」にコピーするファイルタスクでは、
です。 ファイルタスクを定義するためには、ファイルリストに含まれる「コピー元のファイル名」からタスク名である「コピー先のファイル名」を取得する必要があります。 それにはファイルタスクのextメソッドを使います。 extメソッドはファイルタスクに含まれる全てのファイルの拡張子を変更します。
names = sources.ext(".bak")それではRakefileを書いてみましょう。
sources = FileList["*.txt"]
sources.exclude("~*.txt")
names = sources.ext(".bak")
task default: names
rule ".bak" => ".txt" do |t|
cp t.source, t.name
end実行してみます。
(example/example3では-f Rakefile4をつけて実行してください)
$ rake
cp a.txt a.bak
cp b.txt b.bak
cp c.txt c.bak
$上手く動きました。 ここでテキストファイルを増やして、rakeを実行してみます。
$ echo Appended text file. >d.txt
$ rm *.bak
$ rake
cp a.txt a.bak
cp b.txt b.bak
cp c.txt c.bak
cp d.txt d.bak
$新しいファイル「d.txt」もコピーされました。 ということは、Rakefileが「Rake実行時点でのすべてのテキストファイル」をバックアップしたのが確認できた、ということです。
この例の「*.txt」ファイルをソース、「*.bak」ファイルをターゲットということがあります。 一般に、「ソースは存在するが、ターゲットは存在するとは限らない」ということがいえます。 そのため、Rakefileではまずソースを取得して、そのソースからターゲットを生成する、という方法が良く用いられます。
パスマップ・メソッドはファイルリストの強力なメソッドです。 元々はpathmapは、Rakeが拡張したStringオブジェクトのインスタンス・メソッドです。 これをFileListの各要素に対して実行するのがファイルリストのパスマップ・メソッドです。 パスマップは、その引数によって、様々な情報を返します。 よく使われる例をあげます。
パスマップの例示す前に、その準備としてカレントディレクトリに「src」ディレクトリを作り、その下に「a.txt」「b.txt」「c.txt」を作ります。
$ mkdir src
$ touch src/a.txt src/b.txt src/c.txt
$ tree
.
├── Rakefile
├── a.bak
├── a.txt
├── b.bak
├── b.txt
├── c.bak
├── c.txt
├── d.bak
├── d.txt
├── src
│ ├── a.txt
│ ├── b.txt
│ └── c.txt
└── ~a.txt
1 directory, 14 files
$Rakefileを次のように書きます。
sources = FileList["src/*.txt"]
p sources.pathmap("%p")
p sources.pathmap("%f")
p sources.pathmap("%n")
p sources.pathmap("%d")
task :default変数sourcesに代入されるファイルリスト・オブジェクトは「src/a.txt」「src/b.txt」「src/c.txt」を含みます。
では、実行してみます。
(example/example3では-f Rakefile5をつけて実行してください)
$ rake
["src/a.txt", "src/b.txt", "src/c.txt"]
["a.txt", "b.txt", "c.txt"]
["a", "b", "c"]
["src", "src", "src"]パスマップでは、単純な文字列置換を行うための置換パターンを表すパラメータを指定することができます。 パターンと置換文字列はコンマで区切り、全体を波括弧でくくります。 置換指定は、% と指示子の間に置きます。 例えば、「%{src,dst}p」とすると、「src」が「dst」に置換されたパス名が返されます。 これは、「依存ファイル名」から「タスク名」を取得するときに使うことができます。
パスマップの置換指定を使って、「srcディレクトリ以下のすべてのテキストファイルをdstディレクトリ以下にバックアップする」というRakefileを作ってみましょう。
sources = FileList["src/*.txt"]
names = sources.pathmap("%{src,dst}p")
task default: names
mkdir "dst" unless Dir.exist?("dst")
names.each do |name|
source = name.pathmap("%{dst,src}p")
file name => source do |t|
cp t.source, t.name
end
end2行目でパスマップの置換指定を使っています。
sourcesは配列["src/a.txt", "src/b.txt", "src/c.txt"]なのでnamesは配列["dst/a.txt", "dst/b.txt", "dst/c.txt"]になる6行目では、バックアップ先のディレクトリ「dst」が存在しなければ作成します。 mkdirはFileUtilsモジュールのメソッドですが、このモジュールはRakeが自動的にrequireします。 8行目では文字列のpathmapメソッドを使って、タスク名から依存ファイル名を取得しています。
nameがdst/a.txtまたはdst/b.txtまたはdst/c.txtなのでsourceはsrc/a.txtまたはsrc/b.txtまたはsrc/c.txtになるexample/example3フォルダではRakefile6を使って試してください。
[R] 正規表現とProcオブジェクトを使ったルールを用いることもできます。
sources = FileList["src/*.txt"] names = sources.pathmap("%{src,dst}p") task default: names mkdir "dst" unless Dir.exist?("dst") rule /^dst\/.*\.txt$/ => proc {|tn| tn.pathmap("%{dst,src}p")} do |t| cp t.source, t.name end実行してみます。 (
example/example3では-f Rakefile7をつけて実行してください)$ rm dst/* $ rake cp src/a.txt dst/a.txt cp src/b.txt dst/b.txt cp src/c.txt dst/c.txt $ルールを使う方がよりシンプルなRakefileになります。
ディレクトリタスクを作るdirectoryメソッドをこのセクションの最後に紹介します。 ディレクトリタスクは「タスク名のディレクトリが存在しなければ作成する」というタスクです。
directory "a/b/c"このディレクトリタスクは、「a/b/c」というディレクトリを作成するタスクです。 もし、cの親であるb、aも存在しなければ、それも作成します。
これを用いてdstディレクトリを作ることもできます。
sources = FileList["src/*.txt"]
names = sources.pathmap("%{src,dst}p")
task default: names
directory "dst"
names.each do |name|
source = name.pathmap("%{dst,src}p")
file name => [source, "dst"] do |t|
cp t.source, t.name
end
end注意しなければいけないのは、ディレクトリタスクは「タスク」なので、Rakefileのロード実行中はそのタスクが定義されるだけだということです。
ディレクトリの作成にはタスク呼び出しが必要です。
そこで、「dst」を「dst/a.txt」「dst/b.txt」「dst/c.txt」の事前タスクに追加します。
このことにより、コピーの前にディレクトリの作成が行われます。
(example/example3では-f Rakefile8をつけて実行してください)
{R}ルールを使って書き直してみます。
sources = FileList["src/*.txt"] names = sources.pathmap("%{src,dst}p") task default: names directory "dst" rule /^dst\/.*\.txt$/ => [proc {|tn| tn.pathmap("%{dst,src}p")}, "dst"] do |t| cp t.source, t.name endルールの事前タスクにディレクトリタスクが追加されています。 (
example/example3では-f Rakefile9をつけて実行してください)
このセクションではPandocとRakeを組み合わせてHTMLファイルを作成します。 あわせて、CleanとClobberも説明します。
まず、Pandocがどのようなアプリケーションなのかを説明します。 Pandocは、文書の形式を変換するアプリケーションです。 例えば、
これ以外にも多数の文書形式がサポートされています。 詳しくはPandocのウェブサイトをご覧ください。
Pandocの最も簡単な使い方は、端末から
pandoc -o 変換先ファイル 変換元ファイルという形で呼び出すことです。 Pandocはファイルの拡張子からファイル形式を判断します。
例としてexample.docxというワードファイルをHTMLにしてみましょう。
ワードファイルはこんな感じです。
次のように端末から打ち込みます。
-sオプションを使っていますが、これについては後ほど説明します。
$ pandoc -so example.html example.docxこれにより、example.htmlというファイルができます。
ダブルクリックするとブラウザで内容が表示されます。
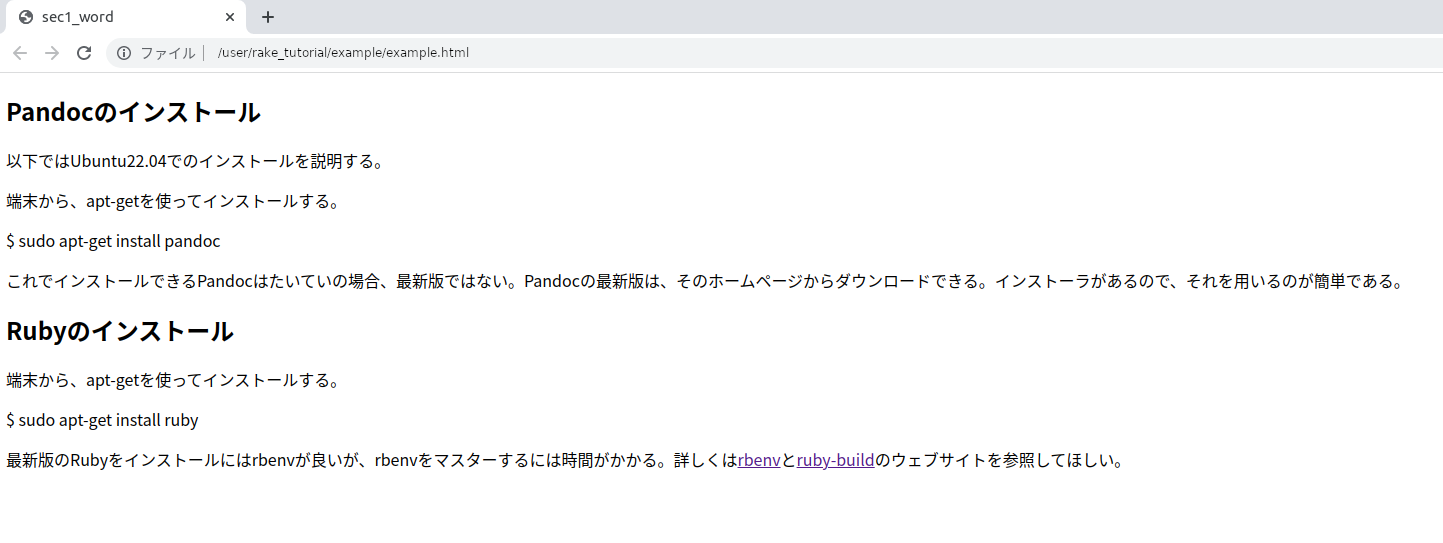
画面の見栄えはともかく、ワードで書いた内容がHTMLとして表示されていることが確認できるでしょう。
では、どのようなHTMLが生成されたのでしょうか。
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" lang="" xml:lang="">
<head>
<meta charset="utf-8" />
<meta name="generator" content="pandoc" />
<meta name="viewport" content="width=device-width, initial-scale=1.0, user-scalable=yes" />
<title>example</title>
<style>
code{white-space: pre-wrap;}
span.smallcaps{font-variant: small-caps;}
span.underline{text-decoration: underline;}
div.column{display: inline-block; vertical-align: top; width: 50%;}
div.hanging-indent{margin-left: 1.5em; text-indent: -1.5em;}
ul.task-list{list-style: none;}
</style>
</head>
<body>
<h2 id="pandocのインストール"><strong>P</strong>andocのインストール</h2>
<p>以下ではUbuntu22.04でのインストールを説明する。</p>
<p>端末から、apt-getを使ってインストールする。</p>
<p>$ sudo apt-get install pandoc</p>
<p>これでインストールできるPandocはたいていの場合、最新版ではない。Pandocの最新版は、
そのホームページからダウンロードできる。インストーラがあるので、それを用いるのが簡単である。</p>
<h2 id="rubyのインストール">Rubyのインストール</h2>
<p>端末から、apt-getを使ってインストールする。</p>
<p>$ sudo apt-get install ruby</p>
<p>最新版のRubyをインストールにはrbenvが良いが、rbenvをマスターするには時間がかかる。
詳しくは<a href="https://github.com/rbenv/rbenv">rbenv</a>と
<a href="https://github.com/rbenv/ruby-build">ruby-build</a>のウェブサイトを参照してほしい。</p>
</body>
</html>HTMLのソースコードから分かることで最も重要なことは、ヘッダが追加されていることです。
これはpandocに-sオプションをつけたからです。
-sをつけなければ、bodyタグで挟まれた本文の部分だけが生成されます。
ここからは、マークダウンをHTMLに変換し、さらにRakeで作業を自動化する方法を学びます。
ソースファイルはすべてカレントディレクトリにあるとします。 生成するHTMLはdocsディレクトリに作成します。 マークダウンファイルは、「sec1.md」「sec2.md」「sec3.md」「sec4.md」ですが、将来ファイルが増えても対応できるようにRakefileを作ります。
サンプルファイルはexample/example4にあります。
その中の「sec1.md」から「sec4.md」は、このチュートリアルの第1章から第4章までのマークダウンファイルです。
(画像の部分は除いています)
Pandocでは、最初に%とともにメタデータを書きます。 これは、タイトル、著者、日付を表します。
% はじめてのRake
% ToshioCP
% 2022/7/25タイトルはHTMLヘッダのtitleタグの内容にもなります。
Pandocで変換したHTMLは画面全面を使うので、横幅のあるPCでは広がりすぎて読みにくくなります。 それを解消するために、CSSファイル「style.css」を用意しました。
body {
padding-right: 0.75rem;
padding-left: 0.75rem;
margin-right: auto;
margin-left: auto;
}
@media (min-width: 576px) {
body {
max-width: 540px;
}
}
@media (min-width: 768px) {
body {
max-width: 720px;
}
}
@media (min-width: 992px) {
body {
max-width: 960px;
}
}
@media (min-width: 1200px) {
body {
max-width: 1140px;
}
}
@media (min-width: 1400px) {
body {
max-width: 1320px;
}
}このCSSはBootstrapのcontainerクラスの定義を参考に作りました。
このCSSは画面サイズに応じて、bodyの幅を調節するものです。
「レスポンシブデザイン」というテクニックです。
内容の詳細は省略しますが、興味のある人は「レスポンシブデザイン」で検索して説明サイトを見つけてください。
これをstyle.cssという名前のファイルにしてRakefileのあるディレクトリに保存します。
Pandocで-cオプションを使うと、生成されたHTMLのヘッダでstyle.cssを取り込むようになります。
それでは、「sec1.md」から「sec4.md」までの4つのファイルからHTMLファイルを作るRakefileを作ってみましょう。 ここで、2つの考え方があります。
どちらにも一長一短があります。 ここでは、作成の簡単な2番目の方法を採用しましょう。
sources = FileList["sec*.md"]
task default: %w[docs/はじめてのRake.html docs/style.css]
file "docs/はじめてのRake.html" => %w[はじめてのRake.md docs] do |t|
sh "pandoc -s --toc -c style.css -o #{t.name} #{t.source}"
end
file "はじめてのRake.md" => sources do |t|
firstrake = t.sources.inject("") {|s1, s2| s1 << File.read(s2) + "\n"}
File.write("はじめてのRake.md", firstrake)
end
file "docs/style.css" => %w[style.css docs] do |t|
cp t.source, t.name
end
directory "docs"タスクの関連が少し複雑になっています。 ひとつひとつ見ていきましょう。
6行目のshは、Rubyのsystemメソッドと似ていて、引数を外部コマンドとして実行します。
6行目ではシェルを介してpandocを起動しています。
shメソッドはRakeがFileUtilsに拡張したもので、オリジナルのFileUtilsにはありません。
Pandocの--tocオプションは目次を自動生成するオプションです。
デフォルトではマークダウンの見出しの#から###までが目次になります。
10行目のinjectメソッドは畳み込みを行う、配列インスタンスのメソッドです。
引数を初期値として、配列の値を次々にs2に代入して計算し、結果を次のs1に代入します。
順を追って説明しましょう
""です。
それがブロックのs1に代入されますs2には最初の配列の要素である「sec1.md」が代入され、ブロック本体のs1 << File.read(s2) + "\n"が実行されます。
これにより、s1の指す文字列には「sec1.mdの内容+改行」が追加され、その文字列が<<メソッドの返り値になります。
その返り値が次に実行されるブロックのs1に代入されます。
(正しく説明すると複雑ですが、要するにs1に「sec1.mdの内容+改行」が足されてそれが次のs1になると考えて差し支えありません)s1は「sec1.mdの内容+改行」、s2には次の配列要素の「sec2.md」が代入されます。
ブロック本体が実行され、「s1」には「sec2.mdの内容+改行」が追加されます。
その結果、s1は「sec1.mdの内容+改行+sec2.mdの内容+改行」となります。
これが次のs1に代入されます。s1には前回実行の結果、s2には次の配列要素の「sec3.md」が代入されます。
前と同様に「sec3.mdの内容+改行」が追加されます。s1には前回実行の結果、s2には次の配列要素の「sec4.md」が代入されます。
前と同様に「sec4.mdの内容+改行」が追加されます。firstrakeには「sec1.mdの内容+改行+sec2.mdの内容+改行+sec3.mdの内容+改行+sec4.mdの内容+改行」が代入されます。
要するに、4つのファイルを改行を挟んで結合した文字列になります。
11行目でそれがファイル「はじめてのRake.md」に保存されます。改行をファイルの末尾に足したのは、一般に「テキストファイルの末尾は改行がある場合とない場合がある」からです。 改行が無い場合に次のファイルを接続すると、2番めのファイルの先頭の文字が行頭に来ません。 すると、見出しの「#」が行頭からずれて見出しでなくなるということが起こりえます。 これを避けるために改行を足しているのです。
(example/example4では-f Rakefile1をつけてrakeを実行してください)
この処理において「はじてのRake.md」というファイルは中間ファイルです。 重要なのはソースファイルと結果ファイルだと考えれば、処理後に中間ファイルは削除したいと思うかもしれません。 そのような操作を行うのがcleanタスクです。 cleanタスクを使うには
rake/cleanをrequireするCLEANの指すファイルリスト・オブジェクト(それも「CLEAN」と呼ぶことにします)に中間ファイルを追加する。
ファイルリストには配列と同様のメソッドが備わっているので、<<またはappend、push、includeメソッドで追加ができる。また、結果ファイルも含めて全て生成ファイルを消去するタスクがclobberです。
以上を付け加えたRakefileは次のようになります。
require 'rake/clean'
sources = FileList["sec*.md"]
task default: %w[docs/はじめてのRake.html docs/style.css]
file "docs/はじめてのRake.html" => %w[はじめてのRake.md docs] do |t|
sh "pandoc -s --toc -c style.css -o #{t.name} #{t.source}"
end
CLEAN << "はじめてのRake.md"
file "はじめてのRake.md" => sources do |t|
firstrake = t.sources.inject("") {|s1, s2| s1 << File.read(s2) + "\n"}
File.write("はじめてのRake.md", firstrake)
end
file "docs/style.css" => %w[style.css docs] do |t|
cp t.source, t.name
end
directory "docs"
CLOBBER << "docs"中間ファイルを削除するには
(example/example4では-f Rakefile2をつけて実行してください)
$ rake clean生成ファイル全てを削除するには
$ rake clobberとします。
このセクションではPandocとRakeを組み合わせてPDFファイルを作成します。 あわせて、名前空間も説明します。
PandocはMarkdownをPDFに変換することができます。 このときPandocはLaTeXを経由してPDFにします。
Markdown => LaTeX => PDF経由する形式をConTeXt、roff ms、HTMLにすることもできますが、詳細はPandocのマニュアルで確認してください。 LaTeXからPDFに変換するのは直接Pandocが行うのではなく、LaTeXエンジンを使います。 LaTeXエンジンは、LaTeXをPDFなどに変換するアプリケーションで、pdfLaTeX、XeLaTeX、LuaLaTeXなどがあります。 ここではLuaLeTeXを使うことにします。
※ pLaTeX、upLaTeXなどのエンジンを好きな読者もいるかもしれません。 PandocはそれらをPDF作成エンジンとしてはサポートしていないようです。 それらのエンジンを使いたい場合はPandocでLaTeX文書を生成し、それをさらにそれぞれのエンジンでPDFにしてください。 Rakeの記述は若干複雑になります。
Pandocに対して、いくつか設定すべき項目があります。 それを、Markdownのはじめにメタデータで記述しておきます。 メタデータはYAML形式で書きます。 YAMLについての詳細は、ウィキペディアまたはYAMLの公式ページを参照してください。
% はじめてのRake
% ToshioCP
% 2022/7/29
---
documentclass: ltjsarticle
geometry: margin=2.4cm
toc: true
numbersections: true
secnumdepth: 2
---%で始まるメタデータは、前のセクションでHTMLを作ったときと同じです。
それぞれ、タイトル、著者、作成日時を表します。
---行で前後を囲まれた部分がYAMLのメタデータです。
ここで設定できる項目にどのようなものがあるかはPandocのマニュアルを見てください。
ここで設定している項目は次の通りです。
以上を「sec1.md」の最初に加えておきます。
今まで見出しに「###」から「#####」を使っていましたが、それではLaTeXのsection、subsectionにならないので、「#」から「###」までに変更が必要です。 手作業では面倒ですから、Rubyプログラムを作って変更します。
files = (1..4).map {|n| "sec#{n}.md"}
files.each do |file|
s = File.read(file)
s.gsub!(/^###/,"#")
s.gsub!(/^####/,"##")
s.gsub!(/^#####/,"###")
File.write(file,s)
endこれをch_head.rbというファイル名で保存し、実行します。
(サンプルファイルはexample/example5に入っています)
$ ruby ch_head.rbこれで見出しの修正はできました。
sec2.mdのフェンスコードブロックの中に長すぎる行があります。
PDFではみ出してしまうので、調整しておきます。
> $ rake
> rake aborted!
> Rake::RuleRecursionOverflowError: Rule Recursion Too Deep: [ ... ...
>
> 最後の1行が長いので、分割して3行にする
>
> $ rake
> rake aborted!
> Rake::RuleRecursionOverflowError: Rule Recursion Too Deep: [~a.txt => ~a.txt =>
> ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt =>
> ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt => ~a.txt]Rakefileは前回のものをPDFに合うように修正するので、比較的簡単に作れます。
require 'rake/clean'
sources = FileList["sec*.md"]
task default: %w[はじめてのRake.pdf]
CLEAN.include %w[はじめてのRake.tex]
file "はじめてのRake.pdf" => "はじめてのRake.md" do |t|
sh "pandoc -s --pdf-engine lualatex -o #{t.name} #{t.source}"
end
CLEAN << "はじめてのRake.md"
file "はじめてのRake.md" => sources do |t|
firstrake = t.sources.inject("") {|s1, s2| s1 << File.read(s2) + "\n"}
File.write("はじめてのRake.md", firstrake)
end
CLOBBER << "はじめてのRake.pdf"フォルダexample/example5の「sec1.md」から「sec4.md」は、すでにメタデータや見出しの修正が終わっています。
それでは、Rakeを実行してみましょう。
(example/example5で実行してください)
$ rake
pandoc -s --pdf-engine lualatex -o はじめてのRake.pdf はじめてのRake.md
$今までよりも少し時間がかかります(約10秒)。
できあがったPDFを確かめてください。 MarkdownがこのようなPDFになるのは便利ですね。
HTMLはウェブでの公開、PDFは手元で見るのに適しています。 次のセクションでは、この2つの作業を1つのRakefileにまとめてみます。
2つの作業(HTML、PDFの作成)を1つのRakefileにするとき、タスクをわかりやすいように整理しておきたいところです。 一般に、整理されていないプログラムは後から修正するのが難しくなります。 これを「プログラムの保守性に問題がある」といいます。 「保守性を高める」ことはプログラム開発において非常に大切です。 ここでは名前空間を使い、プログラムの保守性を高めます。
名前空間は大きなプログラムを作るときに使われる一般的手法で、Rakeに限りません。 今回は次のようにします。
名前空間を定義する構文は
namespace 名前空間の名称 do
タスクの定義
・・・・
endです。 今までは、それぞれの作業はdefaultタスクで起動していましたが、今回はそれぞれに「build」タスクを設けることにします。 「build」タスクは名前空間の下に定義するので
となります。 このように名前空間の下のタスクは「名前空間名:タスク名」のように、コロンでつなげて表します。
名前空間は(ファイルタスクやディレクトリタスクでない)一般のタスクにのみ適用されます。 ファイルタスクはファイル名であり、名前空間の中で定義されたからといってファイル名が変わるわけではありません。 ファイルタスクを参照するときにも名前空間は使われません。
2つの作業を1つのRakefileにするために若干の準備が必要です。
まず、メタデータを作ります。
metadata_html.yml
title: はじめてのRake
author: ToshioCP
date: 2022/7/29metadata_pdf.yml
title: はじめてのRake
author: ToshioCP
date: 2022/7/29
documentclass: ltjsarticle
geometry: margin=2.4cm
toc: true
numbersections: true
secnumdepth: 2「sec1.md」の最初にあった%で始まるメタデータを消去しておきます。 「sec1.md」などは、見出しが「###」から「#####」になっていることを確認しておいてください。
では、Rakefileを書きましょう。
require 'rake/clean'
sources = FileList["sec1.md", "sec2.md", "sec3.md", "sec4.md"]
sources_pdf = sources.pathmap("%{sec,sec_pdf}p")
task default: %w[html:build pdf:build]
namespace "html" do
task build: %w[docs/はじめてのRake.html docs/style.css]
file "docs/はじめてのRake.html" => %w[はじめてのRake.md docs] do |t|
sh "pandoc -s --toc --metadata-file=metadata_html.yml -c style.css -o #{t.name} #{t.source}"
end
CLEAN << "はじめてのRake.md"
file "はじめてのRake.md" => sources do |t|
firstrake = t.sources.inject("") {|s1, s2| s1 << File.read(s2) + "\n"}
File.write("はじめてのRake.md", firstrake)
end
file "docs/style.css" => %w[style.css docs] do |t|
cp t.source, t.name
end
directory "docs"
CLOBBER << "docs"
end
namespace "pdf" do
task build: %w[はじめてのRake.pdf]
file "はじめてのRake.pdf" => "はじめてのRake_pdf.md" do |t|
sh "pandoc -s --pdf-engine lualatex --metadata-file=metadata_pdf.yml -o #{t.name} #{t.source}"
end
CLEAN << "はじめてのRake_pdf.md"
file "はじめてのRake_pdf.md" => sources_pdf do |t|
firstrake = t.sources.inject("") {|s1, s2| s1 << File.read(s2) + "\n"}
File.write("はじめてのRake_pdf.md", firstrake)
end
CLEAN.include sources_pdf
sources_pdf.each do |dst|
src = dst.sub(/_pdf/,"")
file dst => src do
s = File.read(src)
s = s.gsub(/^###/,"#").gsub(/^####/,"##").gsub(/^#####/,"###")
File.write(dst, s)
end
end
CLOBBER << "はじめてのRake.pdf"
endポイントを書きます
sourcesの定義を変えた。
PDFの作成で「sec_pdf1.md」のような中間ファイルが作らる。
sources=FileList["sec*.md"]だと、中間ファイルも拾ってしまうので、それを防ぐためにファイル名を具体的に書いた。--metadata-file=オプションをつけてメタデータを取り込むようにした。gsub!ではなくgsubメソッドを使った。
両者は返り値が違うので、エクスクラメーションつきのメソッドは使わないほうが良い。
(置換が起こらなかったときにnilが返るのでバグになりやすい)異なる名前空間では同じ名前のタスクを定義しても名前の衝突は起こりません。 これは特にプロジェクトが大きいときに有利に働きます。
Rakeの実行においては
rake => HTMLとPDFの両方が作られるrake html:build => HTMLのみ作られるrake pdf:build => PDFのみ作られるrake clean => 中間ファイルが削除されるrake clobber => 生成されたファイルすべてが削除されるこのように使い分けをします。
名前空間はRakefileが大きいときに中身を整理できて便利です。 また、Rakefileはその一部をライブラリとして別ファイルにすることができます。 とりわけライブラリではタスク名が外部と衝突するのを防ぐために名前空間が有効です。
逆に、小規模なRakefileでは名前空間なしでも問題はありません。
名前の衝突回避以外に名前空間が役に立つのは、タスクの分類です。 コマンドラインから呼び出すタスクの数が多いとき、それらを名前空間で整理することが考えられます。 たとえば
# データベース関係のタスク
$ rake db:create
・・・・・
# 投稿関係のタスク
$ rake post:new
・・・・・のように、名前空間でそのタスクを分類するのです。 これによって、ユーザがコマンドを整理して覚えやすくなります。
いままで触れなかったRakeの機能について解説します。 内容は、
rakeコマンドのオプションです。
マルチタスク、テストタスクは次のセクションで説明します。
コマンドラインからタスクを起動するときに引数を渡すことができます。 たとえば、
$ rake hello[James]では、タスク名がhelloで引数がJamesです。
複数の引数を渡したいときはコンマで区切ります。
$ rake hello[James,Kelly]ここで注意が必要なのは、スペースを途中に入れてはいけないということです。 なぜなら、スペースはコマンドラインにおいて「引数の区切り」という特別な意味を持っているからです。
rake hello[James,Kelly] =>
コマンドrakeに対して1つの引数hello[James,Kelly]が渡される。
rakeの中でhelloがタスク名、JamesとKellyがタスクへの引数という解釈が行われる。rake hello[James, Kelly] =>
コマンドrakeに対して2つの引数hello[James,とKelly]が渡される。
rakeはhello[James,が閉じカッコ無しなので、文字列全体をタスク名と解釈し、エラーになる。引数にスペースを入れたいときはダブルクォート(")で囲めば大丈夫です。
$ rake "hello[James Robinson,Kelly Baker]"一方、Rakefileにおけるタスク定義では、パラメータをタスク名の次にコンマで区切って書きます。
task :a, [:param1, :param2]このタスクaはパラメータに:param1と:param2を持ちます。
パラメータの名前には通常シンボルを用いますが、文字列も可能です。
また、パラメータがひとつならば配列にしなくても構いません。
タスクaではアクションがないので、引数の効果はありません。
引数の効果はアクションの中で発揮されます。
アクション(ブロック)には2番めのパラメータとして引数のインスタンス(TaskArgumentsクラスのインスタンス)が渡されます。
task :hello, [:person1, :person2] do |t, args|
print "Hello, #{args.person1}.\n"
print "Hello, #{args.person2}.\n"
endブロック・パラメータは
です。
このとき、コマンドラインから次のようにタスクが呼び出されたとします。
(example/example7でオプション-f Rakefile1をつけて実行してください)
$ rake hello[James,Kelly,David]
Hello, James.
Hello, Kelly.パラメータの数よりも引数の数が多いことに気づいた方もいると思います。 このように数が一致しなくてもエラーにはなりません。
TaskArgumentsクラスのインスタンスメソッドをいくつか列挙します。 上の例を使って説明します。
args[:person1]とするとJamesが返される。args.person1とするとJamesが返される。args.to_aとすると、["James", "Kelly", "David"]が返される。args.extrasとすると、["David"]が返される。args.to_hashとすると、{:person1=>"James", :person2=>"Kelly"}が返される。to_hashのハッシュについてeachメソッドを実行する。[R]上にあげた2番めのパラメータ名をメソッドとして使う方法は、実はメソッドとして定義されたものではありません。 Rakeは
method_missingメソッド(BasicObjectのメソッド)を使い、メソッド名が定義されていなければパラメータ名の値を返すようにしています。 それであたかもパラメータ名のメソッドが実行されたように見えるのです。
パラメータのデフォルト値を設定することも出来ます。
with_defaultsメソッドにハッシュをつけて使います。
task :hello, [:person1, :person2] do |t, args|
args.with_defaults person1: "Dad", person2: "Mom"
print "Hello, #{args.person1}.\n"
print "Hello, #{args.person2}.\n"
endデフォルト値がperson1に対してDad、person2に対してMomになりました。
実行してみます。
(example/example7でオプション-f Rakefile2をつけて実行してください)
$ rake hello[James,Kelly,David]
Hello, James.
Hello, Kelly.
$ rake hello[,Kelly,David]
Hello, Dad.
Hello, Kelly.
$ rake hello
Hello, Dad.
Hello, Mom.タスク定義に事前タスクがある場合はパラメータに続けて=>、事前タスクを書きます。
task :hello, [:person1, :person2] => [:prerequisite1, :prerequisite2] do |t, args|
・・・・
endこの例ではprerequisite1とprerequisite2が事前タスクです。
事前タスクには引数が受け継がれますので、その中でパラメータを設定しておけば引数を使うことができます。
task :how, [:person1, :person2] => :hello do |t, args|
print "How are you, #{args.person1}?\n"
print "How are you, #{args.person2}?\n"
end
task :hello, [:person1, :person2] do |t, args|
print "Hello, #{args.person1}.\n"
print "Hello, #{args.person2}.\n"
endタスクhowに与えられる引数が事前タスクhelloにも与えられます。
(example/example7では-f Rakefile3をつけて実行してください)
$ rake -f Rakefile3 how[James,Kelly,David]
Hello, James.
Hello, Kelly.
How are you, James?
How are you, Kelly?上記の例は実用的ではないですが、読者がRakefileの引数を理解する手助けにはなると思います。
引数以外に環境変数を使ってRakeに値を渡すこともできますが、これは古い方法です。 Rakeはバージョン0.8.0以前では引数をサポートしていませんでした。 そのときには環境変数を使うのが引数に代わる方法でした。 現時点では環境変数を引数として使う必要はありません。
タスクの説明(ディスクリプション
description)をつけることができます。
descコマンドを使い、対象のタスクの前に記述します。
desc "あいさつをするタスク"
task :hello do
print "Hello.\n"
end説明の文字列はタスク定義時にタスクインスタンスにセットされます。
説明はrake -Tまたはrake -Dで表示されます。
$ rake -T
rake hello # あいさつをするタスク
$ rake -D
rake hello
あいさつをするタスク
$表示されるのはディスクリプションがあるタスクだけです。 ディスクリプションは、ユーザがコマンドラインから呼び出す可能性のあるタスクにのみ付けるべきです。 例えば、前セクションのHTMLやPDFを作成するRakefileでは、
・・・・・
desc "HTMLとPDFの両方のファイルを作成します"
task default: %w[html:build pdf:build]
・・・・・
namespace "html" do
desc "HTMLのファイルを作成します"
task build: %w[docs/はじめてのRake.html docs/style.css]
・・・・・
namespace "pdf" do
desc "PDFのファイルを作成します"
task build: %w[はじめてのRake.pdf]
・・・・・とするとコマンドラインからタスクの説明を見ることができます。
(example/example6で-f Rakefile1をつけて実行してください)
$ rake -T
rake clean # Remove any temporary products
rake clobber # Remove any generated files
rake default # HTMLとPDFの両方のファイルを作成します
rake html:build # HTMLのファイルを作成します
rake pdf:build # PDFのファイルを作成しますこれでユーザはどのタスクを使えばよいのかが分かります。 ディスクリプションはユーザのためのコメントだということがいえます。
これに対して開発者がプログラムのメモを残したいときはRubyのコメント(#から改行まで)を用います。
-Tオプションでは1行に収まる分しか表示されませんが、-Dオプションではディスクリプションすべてを表示します。
また、これらのオプションではパターンをつけてタスクを限定することができます。
開発者向けのオプションとしては
-AT => すべての定義されたタスクを表示。
タスク呼び出し時に定義される事前タスクは、この時点では未定義のため表示されません。-P => タスクの依存関係を表示-tまたは--trace =>
すべてのバックトレースを表示とくに、-tまたは--traceオプションは開発の上で有益です。
カレントディレクトリにRakefileが見つからない場合、上位のディレクトリを探していきます。
たとえば、カレントディレクトリがa/b/cで、Rakefileがaにあれば、
a/b/cでRakefileをサーチ => ない。ひとつ上のディレクトリへa/bでRakefileをサーチ => ない。ひとつ上のディレクトリへaでRakefileをサーチ => ある。Rakefileを読み込んで実行。このときRakeのカレントディレクトリはaになる(a/b/cではないことに注意)。また、-fオプションでRakefileを指定することも可能です。
Rakefileは1つのファイルに書くことが多いと思いますが、大きな規模の開発では複数のファイルに分けることが考えられます。 その際は
.rakeの拡張子をつける(ファイル名はRakefileでなくてもよい)rakelibディレクトリにおくこのとき、Rakefileとライブラリにプログラム上の主従関係はないのですが、トップディレクトリのRakefileを「メインのRakefile」ということがあります。
ここでは、マルチタスクとテストタスクを説明します。
ここでいう「マルチタスク」はRakeの「multitask」メソッドを使った処理のことで、一般に使う「マルチタスク」ではありません。 タスクの中には互いに影響を及ぼさないタスクが複数存在することがあります。 そのとき、それらをひとつのスレッドで順に実行するよりも、マルチスレッドにして並行処理するほうが高速です。 そのためのメソッドが「multitask」です。
例としてテキストファイル中の文字を「文字ごとに」カウントするプログラムfre.rbを用います。
example/example8フォルダにこのプログラムが入っていますが、そのソースリストの解説は省略します。
このプログラムは引数で与えられたファイルを捜査し、文字ごとの出現頻度を調べ、文字数と上位10位の文字とカウントを表示します。
$ ruby fre.rb ../../sec1.md
総文字数: 7828
頻度の上位10文字
"\n" => 409
" " => 262
"e" => 229
"`" => 217
"a" => 190
"の" => 162
"す" => 160
"を" => 142
"k" => 141
"で" => 126これにより、総文字数は7828で、最も多く出現したのが改行で409個です。 改行や空白が上位に来ていて、あまり意味がないかもしれませんね。 もう少し先まで表示すれば日本語文字の頻度が分かり、より実用的かもしれません。 その場合は、ほんの少しプログラムを変えれば上位20位あるいは30位にできます。 あるいは、改行などの区切り文字を表示しないようにもできます。
当初の予想では、ある程度時間がかかると思っていたのですが、実行してみると一瞬で終わってしまいました。 マルチタスクのありがたさを実感するには、時間がかかるプログラムの方が良いのですが、更にもうひとつプログラムを書くのも面倒なので、これで説明します。 申し訳ありません。
さて、2つのRakefileを用意します。
Rakefile1とRakefile2です。
Rakefile1
require 'rake/clean'
files = FileList["../../sec*.md"]
task default: files
files.each do |f|
task f do
sh "ruby fre.rb #{f} > #{f.pathmap('%f').ext('txt')}"
end
end
CLEAN.include files.pathmap('%f').ext('txt')このRakefile1は「sec1.md」から「sec7.md」までのファイルの文字出現頻度を調べ、その結果をファイルに書き出します。
Rakefile2もほぼ同様で、異なるのは出力ファイル名を違うものにしたことと、5行目のtaskメソッドをmultitaskメソッドをに代えたことです。
multitask default: filesmultitaskメソッドではタスクを別々のスレッドで並行処理をしますので、速度上の効果が期待できます。
それを調べるためにRubyのBenchmarkライブラリを使って時間計測をしました。
プログラムbm.rbは次の通りです。
require 'benchmark'
Benchmark.bm do |x|
x.report {system "rake -f Rakefile1 -q"}
x.report {system "rake -f Rakefile2 -q"}
endベンチマークライブラリの使い方はRubyのドキュメントを参考にしてください。 実行してみます。
$ ruby bm.rb
user system total real
0.000187 0.000033 0.569095 ( 0.569198)
0.000162 0.000029 0.959387 ( 0.315929)上がtaskメソッドで順にひとつひとつを処理した場合、下がmultitaskメソッドで並行処理をした場合です。 両者とも一瞬で終わってしまうので、体感的には変わらないのですが、上の結果をみるとmultitaskの方が1.8倍速くなっています。
マルチタスクが使えるためには、それぞれのタスクが干渉しないことが前提です。 タスクの組み立てを上手くして干渉しないようにすれば、multitaskメソッドで速度の改善が期待できます。
最後のトピックはテストタスクです。 現在のRubyの標準テストライブラリはminitestです。 minitestの情報はそのホームページにあります。 何回か経験すればテストのコツのようなものは分かると思います。
通常、テストのプログラムはtestディレクトリに集めておくことが多いです。
そのディレクトリにRakefileを置き、テストをマルチタスクで高速に行うことができます。
例がRubyのホームページにありますので、参考にしてください。
ここで実例を作るのはかなり大きな作業になりますので、ここではRakefileとその解説のみにとどめます。
require "rake/testtask"
Rake::TestTask.new do |t|
t.libs << "test"
t.test_files = FileList['test/test*.rb']
t.verbose = true
endこの例では、テスト用のRubyファイルが「test」から始まるファイル名(通常は複数個のファイル)とします。
testtaskをrequireすることが必要ですRake::TestTask.newでテストタスクを生成します。
一般のタスクにはtaskメソッドがありますが、テストタスクはnewメソッドでインスタンスを作ります。tは生成されたテストタスクです。t.libsはライブラリのロードパスで、testディレクトリを追加しますtest_filesメソッドで明示的にテストファイルを示します。
複数のファイルに含まれるテストのあいだにコンフリクトが起こらないようにしてください。
テストプログラムがファイルの読み書きをする場合は特に注意が必要です。t.verbose=trueにすると、テストの実行結果の詳細を表示します。コマンドラインから、testタスクを実行します。
$ rake test以上、Rakeの使い方について初心者向けに解説してきました。 最後は難しい内容になってしまったかと思いますが、前半だけ理解できればRakeは使えるようになります。 後半はある程度使えるようになってから、再学習しても良いと思います。
このチュートリアル自体もRakeを使ってマークダウンからHTMLを生成し、Github Pagesに表示するようになっています。 トップディレクトリにあるRakefileも参考として見てください。
チュートリアルを最後までお読みいただき、ありがとうございました。
Happy Hacking!