GtkDrawingArea and Cairo
If you want to draw shapes or paint images dynamically on the screen, use the GtkDrawingArea widget.
GtkDrawingArea provides a Cairo drawing context. You can draw images with Cairo library functions. This section describes:
- A brief introduction to Cairo
- GtkDrawingArea, with a very simple example.
Cairo
Cairo is a drawing library for two dimensional graphics. There are a lot of documents on Cairo’s website. If you aren’t familiar with Cairo, it is worth reading the tutorial.
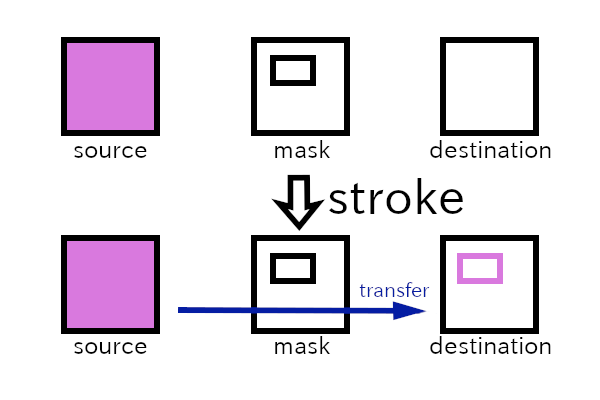
The following is an introduction to the Cairo library. First, you need to know surfaces, sources, masks, destinations, cairo context and transformations.
- A surface represents an image. It is like a canvas. We can draw shapes and images with different colors on surfaces.
- The source pattern, or simply source, is like paint, which will be transferred to destination surface by cairo functions.
- The mask describes the area to be used in the copy;
- The destination is a target surface;
- The cairo context manages the transfer from source to
destination, through mask with its functions; For example,
cairo_strokeis a function to draw a path to the destination by the transfer. - A transformation can be applied before the transfer completes. The type of the transformation is called affine, which is a mathematical term meaning transformations that preserve straight lines. Scaling, rotating, reflecting, shearing and translating are examples of affine transformations. They are mathematically represented by matrix multiplication and vector addition. In this section we don’t use it, instead we will only use the identity transformation. This means that the coordinates in the source and mask map directly to the same coordinates in the destination.
The instruction is as follows:
- Create a surface. This will be the destination.
- Create a cairo context with the surface. This surface will be the destination of the context.
- Create a source pattern within the context.
- Create paths, which are lines, rectangles, arcs, texts or more complicated shapes in the mask.
- Use a drawing operator such as
cairo_stroketo transfer the paint in the source to the destination. - Save the destination surface to a file if necessary.
Here’s a simple example program that draws a small square and
saves it as a png file. The path of the file is
/src/misc/cairo.c.
#include <cairo.h>
int
main (int argc, char **argv)
{
cairo_surface_t *surface;
cairo_t *cr;
int width = 100;
int height = 100;
int square_size = 40.0;
/* Create surface and cairo */
surface = cairo_image_surface_create (CAIRO_FORMAT_RGB24, width, height);
cr = cairo_create (surface);
/* Drawing starts here. */
/* Paint the background white */
cairo_set_source_rgb (cr, 1.0, 1.0, 1.0);
cairo_paint (cr);
/* Draw a black rectangle */
cairo_set_source_rgb (cr, 0.0, 0.0, 0.0);
cairo_set_line_width (cr, 2.0);
cairo_rectangle (cr,
width/2.0 - square_size/2,
height/2.0 - square_size/2,
square_size,
square_size);
cairo_stroke (cr);
/* Write the surface to a png file and clean up cairo and surface. */
cairo_surface_write_to_png (surface, "rectangle.png");
cairo_destroy (cr);
cairo_surface_destroy (surface);
return 0;
}- 1: Includes the header file of Cairo.
- 6:
cairo_surface_tis the type of a surface. - 7:
cairo_tis the type of a cairo context. - 8-10:
widthandheightare the size ofsurface.square_sizeis the size of a square to be drawn on the surface. - 13:
cairo_image_surface_createcreates an image surface.CAIRO_FORMAT_RGB24is a constant that means each pixel has red, green, and blue components, and each component is an 8-bit number (24 bits in total). Modern displays have this type of color depth. Width and height are in pixels and given as integers. - 14: Creates cairo context. The surface given as an argument will be the destination of the context.
- 18:
cairo_set_source_rgbcreates a source pattern, which is a solid white paint. The second to fourth arguments are red, green and blue color values respectively, and they are of type float. The values are between zero (0.0) and one (1.0). Black is (0.0,0.0,0.0) and white is (1.0,1.0,1.0). - 19:
cairo_paintcopies everywhere in the source to destination. The destination is filled with white pixels with this command. - 21: Sets the source color to black.
- 22:
cairo_set_line_widthsets the width of lines. In this case, the line width is set to be two pixels and will result in that size. (It is because the transformation is identity. If the transformation isn’t identity, for example scaling with the factor three, the actual width in destination will be six (2x3=6) pixels.) - 23: Draws a rectangle (square) on the mask. The square is located at the center.
- 24:
cairo_stroketransfers the source to destination through the rectangle in the mask. - 31: Outputs the image to a png file
rectangle.png. - 32: Destroys the context. At the same time the source is destroyed.
- 33: Destroys the surface.
To compile this, change your current directory to
/src/misc and type the following.
$ gcc `pkg-config --cflags cairo` cairo.c `pkg-config --libs cairo`
See the Cairo’s website for further information.
GtkDrawingArea
The following is a very simple example.
#include <gtk/gtk.h>
static void
draw_function (GtkDrawingArea *area, cairo_t *cr, int width, int height, gpointer user_data) {
int square_size = 40.0;
cairo_set_source_rgb (cr, 1.0, 1.0, 1.0); /* white */
cairo_paint (cr);
cairo_set_line_width (cr, 2.0);
cairo_set_source_rgb (cr, 0.0, 0.0, 0.0); /* black */
cairo_rectangle (cr,
width/2.0 - square_size/2,
height/2.0 - square_size/2,
square_size,
square_size);
cairo_stroke (cr);
}
static void
app_activate (GApplication *app, gpointer user_data) {
GtkWidget *win = gtk_application_window_new (GTK_APPLICATION (app));
GtkWidget *area = gtk_drawing_area_new ();
gtk_window_set_title (GTK_WINDOW (win), "da1");
gtk_drawing_area_set_draw_func (GTK_DRAWING_AREA (area), draw_function, NULL, NULL);
gtk_window_set_child (GTK_WINDOW (win), area);
gtk_window_present (GTK_WINDOW (win));
}
#define APPLICATION_ID "com.github.ToshioCP.da1"
int
main (int argc, char **argv) {
GtkApplication *app;
int stat;
app = gtk_application_new (APPLICATION_ID, G_APPLICATION_DEFAULT_FLAGS);
g_signal_connect (app, "activate", G_CALLBACK (app_activate), NULL);
stat = g_application_run (G_APPLICATION (app), argc, argv);
g_object_unref (app);
return stat;
}The main function is almost the same as those in
the previous sections. The two functions
app_activate and draw_function are
important in this example.
- 22: Creates a GtkDrawingArea instance.
- 25: Sets a drawing function of the widget. GtkDrawingArea
widget uses the function
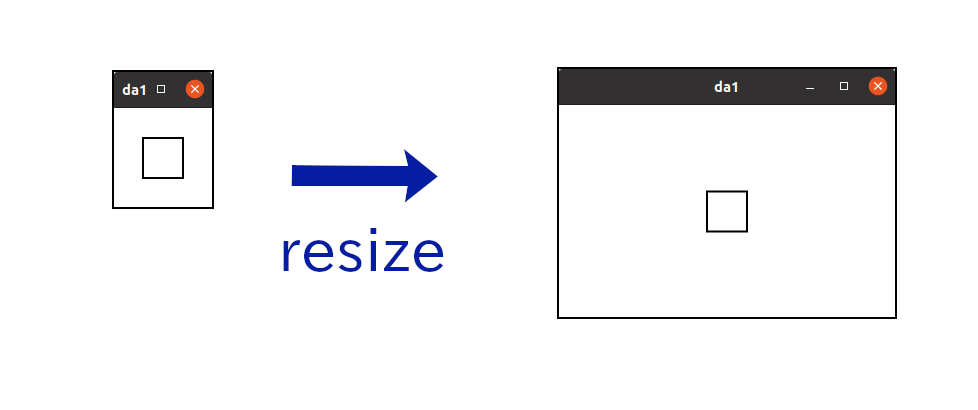
draw_functionto draw the contents of itself whenever it is necessary. For example, when a user drag a mouse pointer and resize a top-level window, GtkDrawingArea also changes the size. Then, the whole window needs to be redrawn. For the information ofgtk_drawing_area_set_draw_func, see Gtk API Reference – gtk_drawing_area_set_draw_func.
The drawing function has five parameters.
void drawing_function (GtkDrawingArea *drawing_area, cairo_t *cr, int width, int height,
gpointer user_data);The first parameter is the GtkDrawingArea widget. You can’t
change any properties, for example content-width or
content-height, in this function. The second
parameter is a cairo context given by the widget. The
destination surface of the context is connected to the contents
of the widget. What you draw to this surface will appear in the
widget on the screen. The third and fourth parameters are the
size of the destination surface. Now, look at the program
again.
- 3-17: The drawing function.
- 7-8: Sets the source to be white and paint the destination white.
- 9: Sets the line width to be 2.
- 10: Sets the source to be black.
- 11-15: Adds a rectangle to the mask.
- 16: Draws the rectangle with black color to the destination.
The program is /src/misc/da1.c. Compile and run it, then a window with a black rectangle (square) appears. When you resize the window, the square always appears at the center of the window because the drawing function is invoked each time the window is resized.